Despite their rigid and often formal, presentation-oriented appearance, PDFs aren’t static documents. They are, in reality, highly complex file structures composed of objects, references, and cross-reference (xref) tables.
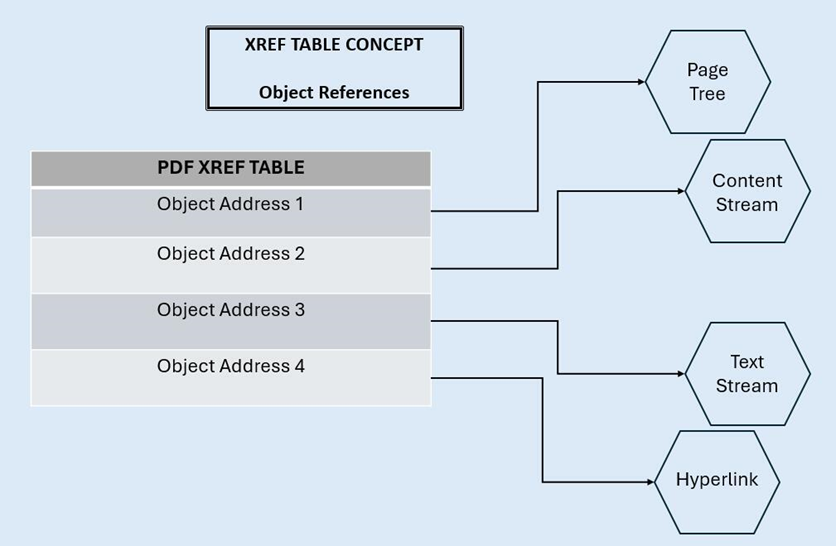
When PDF reader applications navigate a PDF document’s file structure, the xref table is used as a roadmap for locating all the objects stored within the file. This core principle of programmatic PDF navigation can, unfortunately, be exploited quite easily to weaponize PDF uploads.
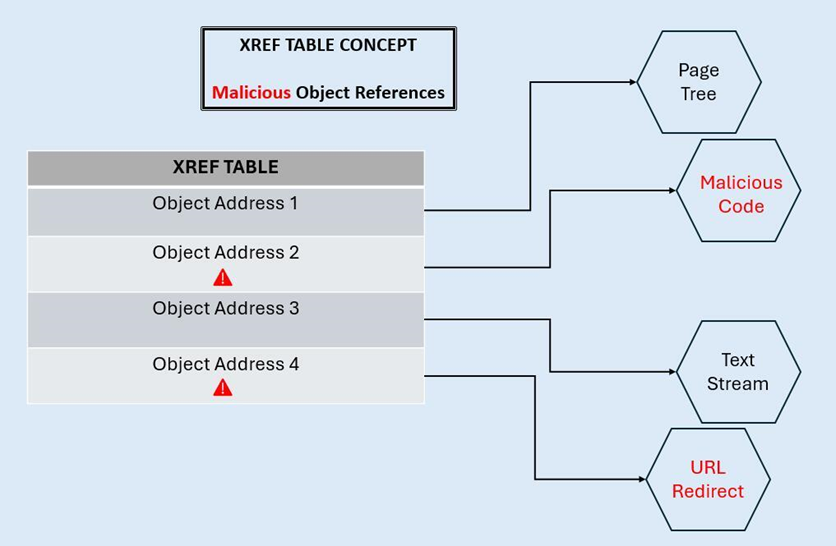
Threat actors can manipulate a PDF’s file structure to change how it’s read and interpreted by PDF reader applications. This makes it possible to hide malicious content, redirect application users to malicious sites, or inject malicious content onto the application or system reading the PDF.
Common Threats in PDF Structure
Concealed components via manipulated xref tables
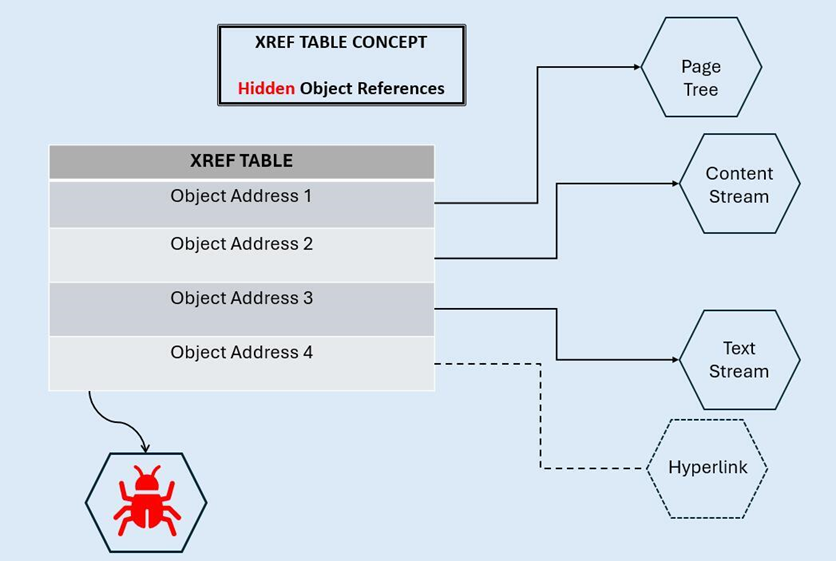
Concealing malicious components is common in complex file structures like PDF. It’s particularly common (and relatively straightforward to pull off) when abusing xref tables.
All applications with PDF reader capabilities use the xref table to locate content within the document, and some of those applications trust the xref table blindly. Typically, that trust exists either because the application assumes xref tables are accurate by the time a file reaches its parsing workflow, or because it simply lacks robust enough validation mechanisms to adequately check the integrity of the PDF structure against the xref table. Either way, this insecure processing behavior opens a significant gap for threat actors to exploit.
Attackers can abuse weakly configured PDF parsers by modifying xref tables to point toward hidden malicious content which wouldn’t normally be reachable. For example, an attacker might embed harmful code (e.g., JavaScript exploits or malware) in a part of the PDF which isn’t visible, and they might subsequently use the xref table to induce the application into thinking this code was a legitimate part of the document. Processing that code could lead to its execution within the application.
Similarly, attackers can create xref table pointers to objects which are present in the PDF but not directly referenced by any legitimate part of the document’s structure. The parser might activate these malicious “unreachable” objects when the PDF is opened.
Triggering memory overflows via unexpected xref entries
When an application’s PDF parser reads a PDF document, it typically expects xref table entries to follow a precise format and a specific length. If these entries exceed the expected format and length, the application can run into serious memory management problems. The information exceeding the expected quantity can literally overflow into other parts of the computer’s memory which aren’t meant for it.
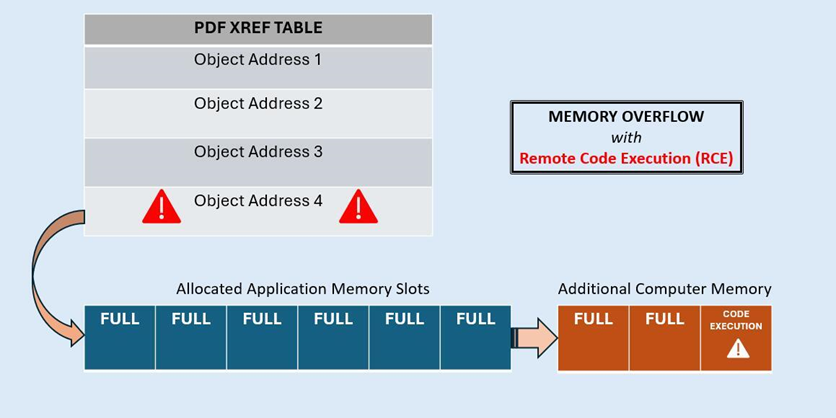
An attacker can induce this scenario by intentionally creating xref tables which defy typical formatting and length expectations. If the attacker is clever enough, they can make the excess information be harmful code which the computer inadvertently executes when memory overflow occurs. This can lead to remote code execution (RCE), which can give the attacker full control over the computer.
Warning Signs of Malicious PDF Structure
Well-configured PDF analysis tools can often identify threats within the file structure by reviewing various content properties.
For example, hidden JavaScript code in a PDF document can often be identified based on the presence of keywords like /JS, /JavaScript, /OpenAction, or /AA (auto-action). If that code is intentionally obfuscated, the warning signs can be out-of-place entities like heavily compressed streams, hex encoding, and other indicators. Robust analysis tools can also identify malicious code based on the type of behavior it intends to enact. If code intends to access system files, connect to insecure external websites, or perform other actions beyond the usual scope of PDF viewing, it’s a strong indicator of malicious intentions.
The same is generally true for malicious links and malicious embedded files. Hyperlinks, for example, might be identifiably suspicious if they’re hidden behind legitimate-looking text or images, or if they can be shown to redirect from the expected landing page to some unexpected external sites. Embedded files might appear suspicious if they have executable extensions (e.g., .exe) or if the PDF has commands to open and execute the files automatically when the document is processed.
Malicious xref entries also bear their own set of suspicious indicators. For example, an xref table which doesn’t follow the standard 20-byte format might indicate an attempt to trigger a memory overflow, and one that points to non-existent objects might indicate an attempt to hide or manipulate content by making the PDF reader ignore certain parts of the file. Excessive xref markers might suggest a threat actor appended unexpected content at the end of a PDF, and gaps in xref entries might indicate suspicious misdirection within the file.
Detecting Corrupt PDF Documents with Cloudmersive
In addition to providing robust virus and malware scanning services, Cloudmersive’s Advanced Virus Scan API also validates file structures to identify suspicious abnormalities. For PDF documents, that includes identifying malformed xref tables, non-standard document trailers, and embedded scripts, objects, and insecure embedded file types.
The Advanced Scan API’s deep content verification capabilities ensure PDFs and all other supported file types rigorously conform with the formatting specifications laid out by the format provider. This ensures file structures align with the parsing routines enterprise applications depend on before they’re processed.
Scanning PDFs and other files with Cloudmersive’s Advanced Virus Scan API within individual web applications, at the network edge, or at rest in cloud object storage containers prevents insecure parsing outcomes from occurring in sensitive enterprise applications.
Final Thoughts
PDF file structure is complex and highly exploitable. PDF parsers rely on internal document references to navigate to content stored within the file, and those references can be manipulated by threat actors to induce insecure file parsing outcomes. Thankfully, they can also be detected by robust PDF analysis tools like Cloudmersive’s Advanced Virus Scan API.
To learn more about verifying PDF files with Cloudmersive, please feel free to contact a member of our team.


 Technical Articles
Technical Articles Virus Scan APIs
Virus Scan APIs Content Disarm and Reconstruction APIs
Content Disarm and Reconstruction APIs Spam Detection APIs
Spam Detection APIs Document Conversion & Processing APIs
Document Conversion & Processing APIs Document AI APIs
Document AI APIs Natural Language Processing (NLP) APIs
Natural Language Processing (NLP) APIs Optical Character Recognition (OCR) APIs
Optical Character Recognition (OCR) APIs Image and Face Recognition and Processing APIs
Image and Face Recognition and Processing APIs